Google, Yahoo, and Microsoft stopped being transport layers years ago. Apple did the same from one layer up, through Mail on iOS and macOS. The four have become active intermediaries between brands and their customers, mediating visibility, extraction, ranking, and interaction. They have spent the last decade publishing papers and patents about how this works. Most of it is open and citable.
The inbox is a parser, not a mailbox
The premise running through every paper from the major providers: consumer email is dominated by machine-generated, templated B2C messages. Yahoo measured north of 60% of inbound from mass senders in 20131. Yahoo's own follow-up work in 2014 put the figure at 90% of non-spam web mail2, and Whittaker et al. cite the same 90% figure for Gmail in 20193. Bentley's 2017 CHI study found 67% of users name "receive coupons and deals" as a top-three use of email, and 56% had searched their inbox for a receipt or shipment in the past week4.
Because the inbox is mostly templated, providers stopped treating it as messaging and started treating it as data extraction.
ML in the inbox predates this timeline by 15 years. Bayesian spam filtering at Microsoft Research dates from 1998 (Sahami, Dumais, Heckerman, and Horvitz)5. What's expanded since is the scope. The 1998 task was disposition: deliver, or send to junk. Everything below is about what happens after disposition. How the message appears, when, with what label, with what summary, and increasingly whether the recipient needs to open it at all. The consumer-mail market also consolidated over the same period: top-three concentration went from 55% to 85% across 2006-20126. Free-tier storage, search quality, mobile and desktop OS bundling, and switching costs did most of that work, with spam-filtering economies of scale as one contributing factor. Three server-side providers dominate the consumer mailbox: Google, Microsoft, Yahoo. Apple is the fourth player this post discusses but at a different layer: Apple Mail on iOS and macOS mediates client-side, on top of whichever service the user has connected. Different architecture, same kind of mediation.
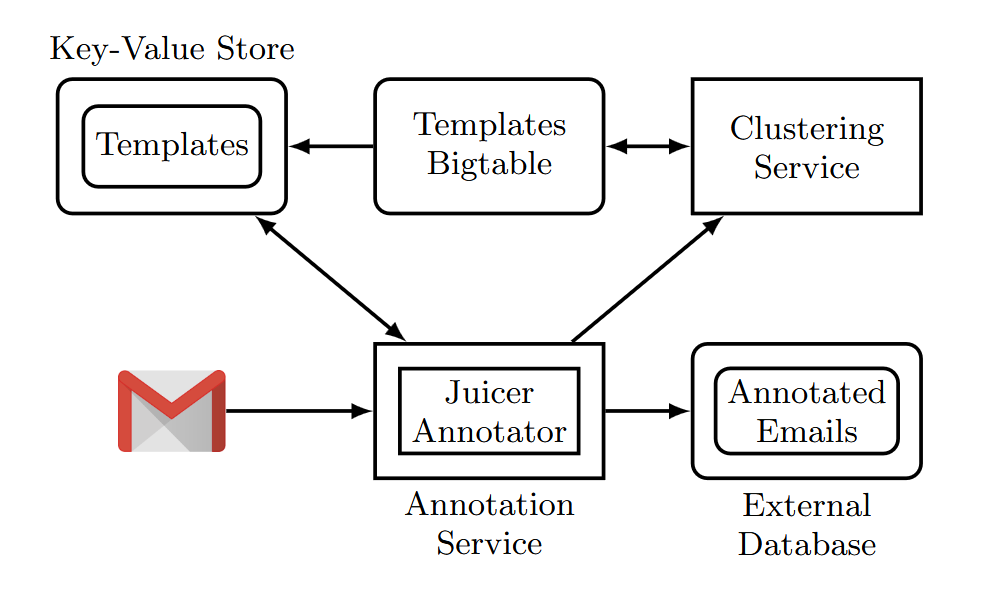
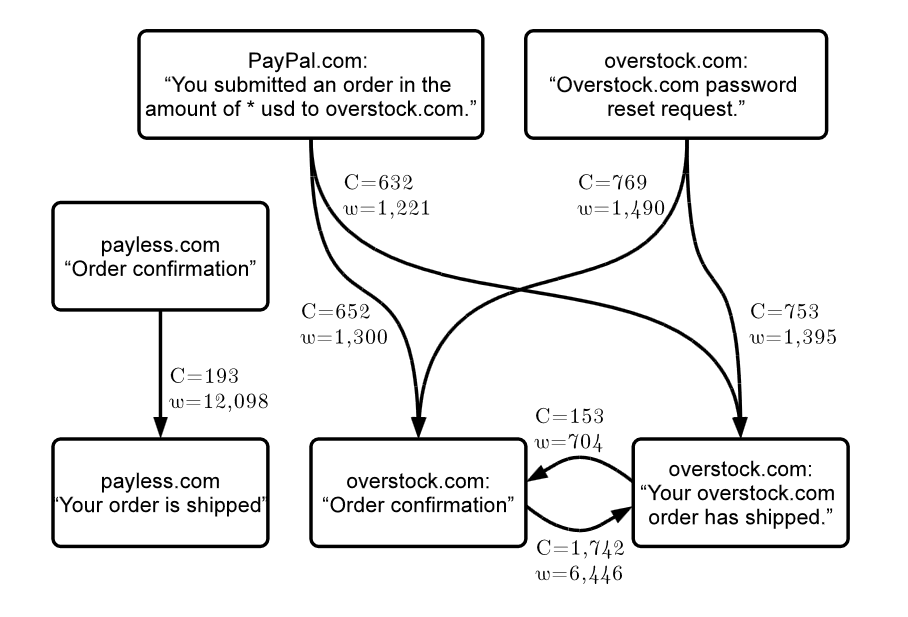
Messages get clustered into templates by hashing the DOM/XPath structure of the HTML3, 7, 8. A k-anonymity threshold (a minimum number of unique recipients for the template to be processable) gates whether a template gets analysed at all3, 8. Below the threshold, you're invisible to the ML pipeline. Once a template clears k-anonymity, field extractors pull structured data (order numbers, prices, tracking numbers, hotel addresses) for use in Search, Assistant, and proactive cards7, 9. The scale is real: Google's Crusher system discovers 1.5 million new templates every week3, so the corpus of recognised B2C senders is constantly expanding rather than being a fixed list.
Gmail's team moved this whole pipeline from hand-written rules to ML models in 2020. They deleted 45,000 lines of rule code in the process10. The HTML structure itself, which tags you use, what's bolded, what's centred, is now a feature in the classifier9. The granularity has also exploded. Yahoo's 2014 work identified 6 latent categories from email folders via LDA: human, career, shopping, travel, financial, social2. Yahoo's most recent classifier (SPICE, 2023) labels 96% of English messages into a 119-class taxonomy of topic + type + objective, all at delivery time, using only your sender name and subject line11. The leap from 6 categories to 119 multi-faceted labels in less than a decade reflects how granular the provider-side classifier has become.
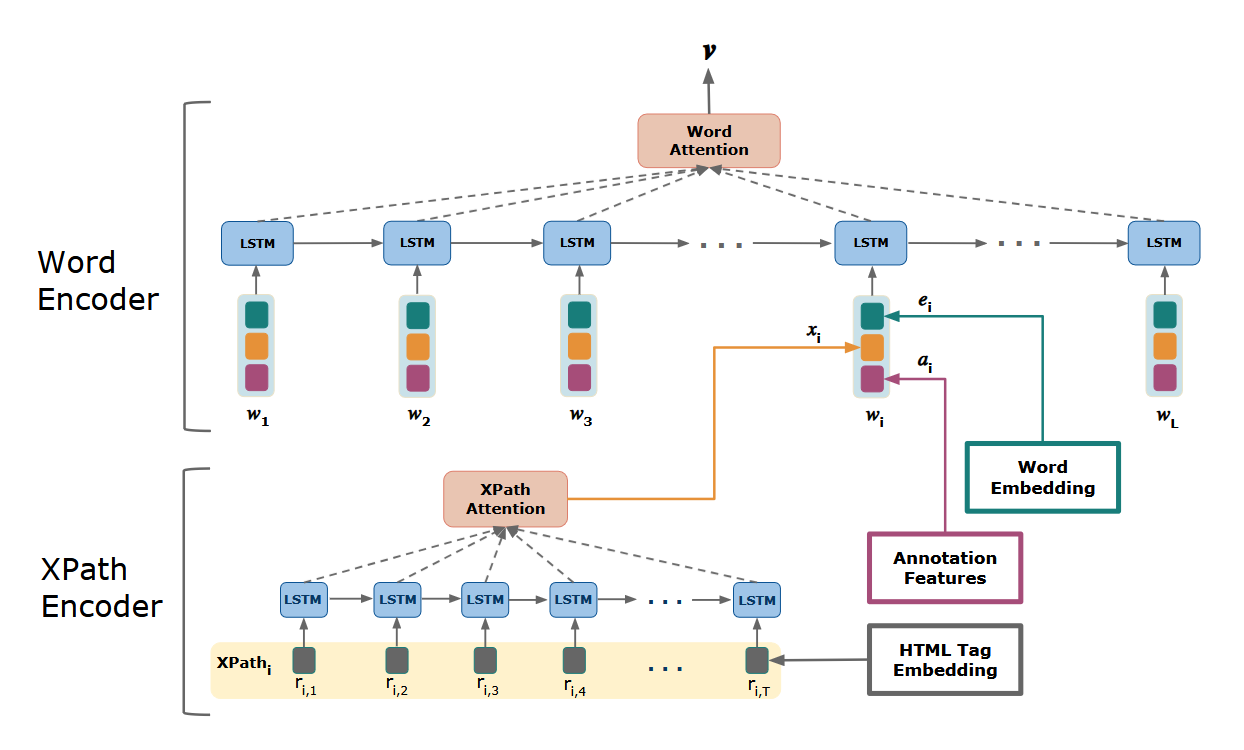
Google's layout-aware document encoder, patented in 2025, treats font-size, is_bold, is_italic, is_underline, colour, and position as block-level features and describes representations that could be used for classification, retrieval, summarisation, and personalising advertisements12. Bigger, bolder, higher on the page would carry more weight than smaller, plainer, further down. The layout encodes a hierarchy the parser can read.
Four practical consequences follow.
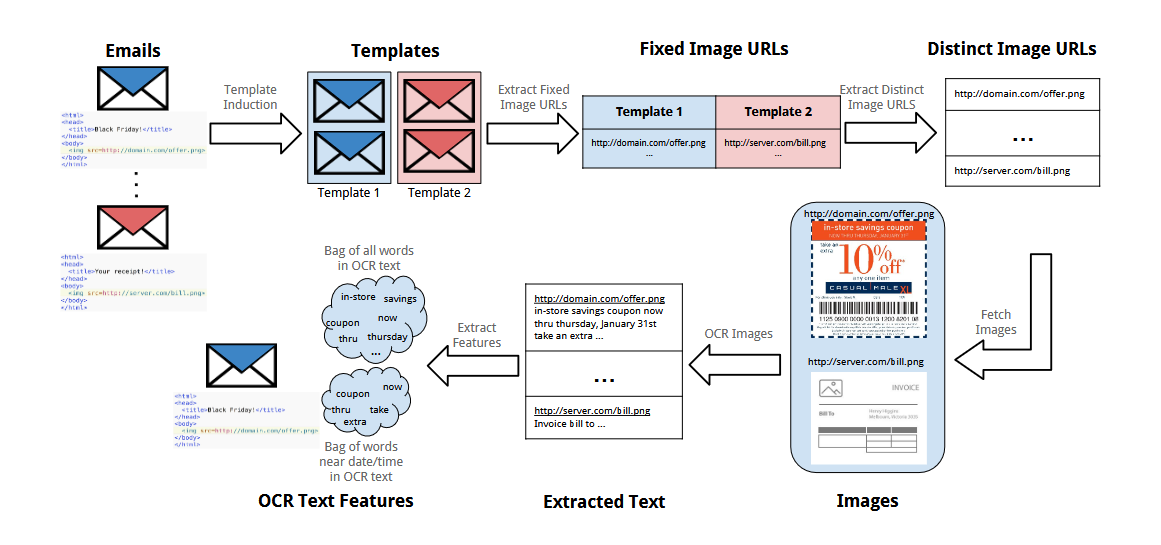
Image-only emails lose context, not text. OCR pulls the words out of pixels. Google documented this exact pipeline in 2018: an OCR pass over images in B2C templates lifted offer-template detection by 9.12%13. What OCR cannot recover is the DOM structure or the block-level attributes. The same paper's feature engineering proves the point: the classifier has separate features for words in bold or large font and words in the footer, populated from the HTML rather than from OCR text13. To the model, your headline, your promo code, your body paragraph, and your legal footer all parse the same flat way out of OCR. Alt-text doesn't fill the gap either: the paper found 47% of email images have empty alt-text and 40% have just one word13. The DOM is the data. The design isn't.
Schema markup is the mechanism that gives creative freedom back. This is the inverse of how marketers usually think about structured email. Schema isn't a constraint on creativity. It's the safety valve that lets a brand depart from the visual conventions of its category without losing parse coverage. If your DiscountOffer, OrderStatus, EventReservation, or FlightReservation annotations stay consistent, you can ship wildly different visual templates campaign to campaign. The provider's ML works off the markup; the recipient sees the design. Frequent visual churn doesn't break extraction. The catch: adoption is low. Most B2C senders don't ship structured annotations at all, and most ESPs make it harder than it should be to set them up properly. The brands that do it are working off a less crowded surface.
Well-structured mail is a queryable customer record. Once parsed, structured email becomes part of the recipient's searchable history of their relationship with your brand. Receipts, confirmations, account updates, and offers persist as records the recipient can retrieve months later via Gmail search, Outlook search, or, increasingly, the LLM assistant connected to their mailbox. That recall value is asymmetric: a clean structured message can be cited by a Gemini or Copilot or Apple Intelligence summary years after sending. An image-only campaign can't. The clearer your content structure, the more durable its presence in the recipient's information environment.
Actionable cards are the sanctioned way to be interactive inside the inbox, with the asterisk that nobody actually adopted them. Microsoft's Actionable Messages patent claims a JSON schema (MessageCard, ActionCard, OpenUri, HttpPOST, MultiChoiceInput, TextInput) that lets senders embed buttons, inputs, and multi-step actions directly in the email, with automatic threading14. The patent's own framing positions plain HTML email as "generic, undifferentiated" clutter. Gmail's AMP for Email follows the same logic. The catch: AMP for Email has been a near-total industry flop, and the bottleneck was upstream of marketers. ESP adoption stayed incredibly low. Few major sending platforms ever built out the infrastructure to support it, which left most marketing teams with no path to ship AMP campaigns even when they wanted to. Google has quietly de-emphasised it since. Microsoft's Actionable Messages saw enterprise adoption (where IT teams could integrate it directly into internal Exchange) but limited B2C uptake for the same reason. The structural argument is still right: the providers want this surface to exist. The practitioner reality is that the runway never opened.
Gmail's Promotion tab Annotations and the resulting Deal Cards are the live version of this argument. A campaign with DiscountOffer schema can surface a visual card at the top of the Promotions tab showing the offer headline, discount, and expiry, generated entirely from the structured markup. The card sits above the email itself. The recipient may take the action without ever opening the message. Same structural logic, different surface, much better adoption than AMP.
The k-anonymity floor cuts the other way too. Hyper-personalised, low-volume, transactional-feeling campaigns may not be processed through the same ML extraction pipeline. Whether that's good or bad depends on what you wanted.
Google's OCR pipeline was built on top of image-fetching infrastructure already in place (Image Proxy since 2013), and that order matters. Once a provider sits between every commercial email image and every recipient, caching the bytes and serving them server-side, adding OCR is incremental compute rather than a new fetch pipeline. The precondition is image proxying at scale. The downstream is visual extraction.
Apple is now in the same architectural position. Mail Privacy Protection (2021) pre-fetches every image in every email upon delivery, regardless of whether the recipient ever opens. MPP was widely read as the privacy story: senders can't see opens. The architectural byproduct is that Apple has the bytes of every commercial email image flowing through Apple servers. That is the substrate Google leveraged for OCR. Apple has not announced a visual-extraction layer of its own. The foundation is built either way.
Microsoft has the same substrate via a different door. Microsoft Defender for Office 365 pre-fetches email content server-side before delivery: URLs through Safe Links, attachments through Safe Attachments sandboxing, and the message body itself. The stated reason is security rather than privacy or serving, but the architectural result is the same: Microsoft has the bytes. The pre-fetch is visible to marketers because it generates well-documented phantom opens and clicks at scale, often under a recognisable "OutlookSafeLink" user agent. Whether Microsoft pivots that infrastructure toward ML extraction the way Google did is the same open question as with Apple.
The pattern across all four providers is the same. Each has built crawler-of-record infrastructure for its own stated reason: serving and privacy at Google and Yahoo, privacy at Apple, security at Microsoft. The substrate is now universal. The visual-extraction precedent is established. Which providers move that direction next is a product decision, not an infrastructure one.
Opens are dead. Actions decide everything.
The actions worth predicting, per Yahoo's research on machine-generated email: read, reply, delete, and the separately modelled delete-without-read15. 85% of messages are never read at all. 89.5% of all deletes happen without the message being opened15. The header is enough to make the call.
Alrashed et al. (Microsoft, working on Outlook enterprise data) found 36% of emails have a lifetime under 5 minutes. 63% under 5 days16. The few messages that get revisited (median: four times) are the ones containing instructions, documents, receipts, or links the user keeps coming back to find16.
Yahoo's email search work uses user actions (read, replied, forwarded, flagged, foldered) as ranking features, and these contribute more to rank than message-sender importance17. The sender's "importance" as a feature turned out to be surprisingly weak17. Action prediction informs ranking, importance, and bundling decisions inside the client15, 17.
The recipient decides on your message from the envelope. Sender name, subject line, snippet. No open required. Yahoo's delivery-time classifier uses only sender and subject11. Subject lines and sender identity do disproportionate work, because they're the only signals available before the decision happens.
Apple Mail shipped Priority Messages in October 2024 as part of Apple Intelligence (opt-in, supported hardware only), a section at the top of the inbox showing emails the model predicts the recipient should act on. That is the action-prediction patent literature landed as a shipping product. The same call Yahoo's papers described a decade ago, now surfacing the model's predicted-action emails above the rest of the inbox for recipients with it enabled. Google followed in January 2026 with AI Inbox, the same action-prediction-as-priority-view pattern at Gmail. AI Inbox's VIP identification explicitly uses behavioural signals (email frequency, contacts membership) and content-derived inferences (relationships extracted from message content).
Microsoft's smart-reply patent describes a client where only a truncated version of inbound messages ("top N message threads" or "message headers only") is sent to the device while the full message and attachments stay on the server until needed18. The user replies from what they see. If implemented that way, content below a header or preheader cutoff may not be downloaded at all before the engagement decision; heavy media and below-the-fold detail can be skipped not by user behaviour, but by client design.
Microsoft also patents a "relevancy engine" that, once a message's time-related metadata has passed the current date, can "archive the electronic message, delete the electronic message, filter the electronic message from view, or provide a visual indication" deprioritising it19. The system uses natural-language patterns including "expires", "good until", "RSVP by", "save the date", "newsletter", "itinerary", "delivered", "statement", and "boarding pass" to identify time-sensitivity at delivery time19.
Expiry dates in your copy are parseable as structured signals. After the date passes, the inbox can hide or deprioritise the message. "This offer expires Friday" can function as a self-destruct timer at the provider layer.
Opens were dead before action prediction got involved
There's a simpler, more proximate reason open rates stopped meaning what they used to mean. Gmail and Apple have both built layers between the sender's tracking pixel and the recipient's actual view. Gmail has routed all email images through Google Image Proxy since 2013, caching them server-side and breaking the link between the open event and the recipient's IP, device, or location; Gmail also pre-fetches images when its app has an active session, producing roughly 1-6% of Gmail opens as false events per SparkPost's analysis of ~10 billion opens. Apple Mail Privacy Protection, shipped with iOS 15 in 2021, went much further: MPP pre-fetches every image in every email upon delivery, regardless of whether the recipient ever opens the message. For senders with Apple Mail recipients (a meaningful share of most consumer lists by the time MPP shipped), every email registers as "opened" immediately, and the metric becomes near-useless. Most teams adapted by shifting toward click rates, conversions, or composite engagement scores.
Action prediction is the deep reason. Gmail's image proxy and Apple's MPP are the proximate ones. Both providers belong in the picture.
Optimising for opens damages everything else
The signals are coupled. A subject line that lifts opens through misdirection or pattern interrupts will often lift delete-without-read at the same rate. Net: the opens metric looks better, the action-prediction model sees a sender whose recipients open and immediately discard, and the engagement profile that drives future placement gets worse. Short-term wins on the cheap metrics compound into longer-term deliverability damage.
This compounds across the cohort, not just per recipient. Consistent low engagement from a sender pushes their mail toward less prominent placement across all recipients, not just the disengaged ones. The provider's classifier doesn't reset between recipients; it treats sender-level engagement signals as a feature of the sender. Bad engagement on the dormant 70% of a list damages reach to the engaged 30%. The classical "set and forget" approach to disengaged segments is now actively expensive.
The flip side: "reference-value" content (receipts, instructions, confirmations, tickets) earns multiple revisits and durable inbox presence even when initial engagement is low. Pure promotional content gets the single brief look and the delete. Transactional and utility content keeps living in the inbox as a resource the user comes back to find.
Personal email left. Commercial email never did.
Bentley's CHI 2017 study is unusually direct: 41% of Americans say email is "not important" for personal communication4. One of his participants put it like this:
If a person is emailing you it just doesn't make sense.
Person-to-person communication moved to WhatsApp, iMessage, Facebook Messenger. Yahoo's threading work was already saying as much in 2013, when they found more than 60% of traffic was from mass senders1. Yahoo Mail 6 was redesigned around this premise, making Deals, Travel, and Receipts top-level navigation surfaces, replacing the unified inbox as the primary view for many users20. Bentley's cross-country survey found 72-86% of users across eight countries use email for receipts, and 69-82% for deals and offers20.
The inbox is, for most consumers, a CRM-of-record for their commercial life.
You're not competing with friends and family for attention. You're competing with other brands inside a dedicated commercial space. That's liberating (deal-seekers actively go to a Deals view) and constraining (your message is one of dozens of structurally similar promotional templates, and the user's mental model is "scan for the offer I want," not "read the email"). The "personal-feeling" tone that worked in 2010 reads as cognitive friction when the user is browsing a Deals tab.
It's also a useful clarifier for what email is and isn't to the brand. The address may belong to you, the consented permission to send may belong to you, but the surface area where the message lands is operated by Google, Yahoo, Apple, or Microsoft. The inbox provider sits between you and the recipient and influences what gets shown, summarised, bundled, expired, or surfaced for unsubscribe. Calling email an "owned channel" was always shorthand for "less rented than social." That shorthand has been wearing thin for a decade, and the gap between owned and rented has narrowed further with every paper and patent below. The ownership question gets its own treatment later.
The media-style newsletter exception
There's a category that occupies a different cell of this grid. Editorial and longform newsletters, single-author voice, prose-heavy, are commercial in the sender-volume sense but content-wise read closer to personal correspondence. They tend to earn high revisit rates and low delete-without-read rates because the recipient signs up for the writer, not the offer.
The classifier sees them differently. SPICE-style topic + type + objective taxonomies have categories for newsletters and editorial content distinct from promotional offers11. The action-prediction models see different behaviour patterns from these senders (more read events, longer dwell time, fewer immediate deletes). The Promotions tab is not their natural home.
For brands, that opens a question. A well-written editorial newsletter from your brand may live in the primary inbox view in a way a pure promo campaign generally won't. It may also survive AI summarisation better, on the working hypothesis that a summary of editorial content tends to represent the content reasonably ("argues X, references Y") in a way a summary of a promo email may not ("30% off, expires Friday" and not much else). If that hypothesis holds, editorial content is functionally less mediated than promotional content despite going through the same pipes. The trade-off is that editorial requires editorial, not the same campaign engine that ships your weekly offer email. Most brands that try this end up shipping promo copy in newsletter wrapping, which the classifier sees through quickly.
Volume coping is structural, not editorial
The papers document how users cope with volume. The numbers are blunt:
- Average user has 93 mailing-list subscriptions in their primary account4.
- Average ~3,500 unread messages in active accounts. Only 35% of users are "caught up"4.
- 20% of users unsubscribed from at least one list in the past week. 27% in the past two weeks4.
- 25% of new email accounts get created specifically to escape mail volume from an old account4.
- Mass-select-and-delete entire screens is normal. The inbox is a feed, not a task list4.
The cost of an annoying campaign isn't "they ignored this one." It's the unsubscribe, the account abandonment, and the engagement-history damage that gets applied to your future sends. The reputation cost of frequency mistakes is way higher than the per-message cost.
Auto-rule creation works against you when your campaigns are too consistent
Microsoft patents automatic detection of repeated email patterns. Once the count of similar messages exceeds a threshold, the inbox surfaces a pop-up offering to generate a folder and create a rule that moves matching messages there automatically21. Both the historical batch and all future matching messages get moved out of the inbox into the user folder. Microsoft research has continued to push this further: EmFore (2023) is an online system that learns symbolic folder-classification rules from user behaviour, updating the rules in real time after every incoming email22, rather than waiting for a fixed threshold to trigger a suggestion.
Here's the tension: a campaign with stable subject patterns and a consistent sender domain (exactly the conditions the ML extraction pipeline prefers) is also exactly the pattern that triggers user-side auto-rule creation. Same template stability that helps the provider's ML categorise you correctly turns into rule-fodder for the recipient.
The countermove: category stability with content variation. Same schema markup vertical, varied subject phrasing, varied sender display name within the same domain.
Provider-initiated unsubscribe is the new sunset policy
Two features compound here. The first is the proactive unsubscribe banner Gmail, Yahoo, and Outlook have shipped on inbound from senders the user rarely opens. The mechanism is the action-prediction model run in reverse: when the per-sender predicted-action distribution skews heavily toward delete-without-read, the inbox surfaces a one-click unsubscribe at the top of the message.
The second is dashboard-style subscription management. Gmail's Manage Subscriptions, rolled out from July 2025, lists every brand the recipient is subscribed to, ranked by sending frequency, with one-click unsubscribe. Recipients who would never have hunted through individual emails to opt out can now decommission dozens of senders in a session. Yahoo runs the equivalent under the name Subscription Hub, with the same one-click unsubscribe mechanics, gated to senders who support RFC 8058 (or mailto: unsubscribe per RFC 2369) and meet Yahoo's reputation and engagement thresholds. Outlook is still partial on this specific surface as of mid-2026.
These work together with the unsubscribe banner. The dashboard surfaces who emails most often. The banner surfaces who emails most often without engagement. A sender hitting both ("high frequency, low engagement") gets a recipient prompted to remove them from two different directions in the same interface.
This makes the "what does it cost to send to disengaged subscribers" question urgent in a way it wasn't five years ago. The classical answer was "almost nothing, the marginal cost of a send is fractions of a cent." That answer is now wrong. Continuing to send promotional volume to a dormant segment trains the provider that your sender profile skews toward low-engagement, which damages reach to your engaged segment. It also increases the surface area for the recipient to be prompted to unsubscribe, which is now functionally a one-click action surfaced in two different UIs. The cost of sending to dead-weight subscribers isn't zero. It's the engagement-cohort drag on your active sends plus the accelerated permanent loss of the dormant cohort.
Apple Mail collapses your brand to a single line
Apple Mail's Brand Message Grouping rolls multiple emails from the same brand into a single visual unit in the inbox view, showing two subject lines and an "Older messages" affordance for the rest. The brand-level surface area collapses regardless of how many campaigns you send in a window. Three sends a week now occupies the same visual real estate as one send a week. If anything, the high-frequency sender's incremental sends are visible only to the recipient who taps to expand the group.
Combined with the Manage Subscriptions view, the implication is the same: frequency is no longer free. It's negatively correlated with per-message visibility.
Being in Promotions is fine. Being parsed badly isn't.
The Promotions tab is not a punishment. Deal-seekers actively browse it; that's its job. The trade-off is that messages in Promotions get scanned, not read. A promotional message that lands in Promotions is in its right home.
Since September 2025 there's a second-order question: where inside Promotions does your message rank? Gmail's default sort is now relevance, not recency, which means within-tab placement is engagement-weighted. Senders with strong cohort engagement get pinned near the top of an actively-scanned surface. Senders with weak engagement get buried under the fold. The "lands in Promotions" outcome that used to be uniform is now bimodal: it's a good outcome for engaged senders and a worse outcome than it used to be for disengaged ones.
The actual problem categories underneath this are different. Being below the k-anonymity floor (invisible to the ML extraction pipeline, no Assistant card, no Deals view inclusion). Being below the engagement gate (filtered out of search results, retrieval suppressed). Being routed to spam (deliverability failure). "Promotions" is the natural home for the bulk of B2C marketing email. Treating Promotions placement as a failure case usually means you're optimising for a metric that doesn't matter (primary tab placement) over ones that do (engagement-history compounding, parse coverage, search retrievability, within-tab ranking).
AI is now between you and the recipient
The product timeline matters here. Microsoft shipped a Copilot Summarize button in Outlook desktop in March 2024. Google announced Gemini in Gmail at I/O in May 2024 (summarise, draft, search across the inbox). Apple announced Apple Intelligence at WWDC in June 2024 and shipped the Mail features in iOS 18.1 in October 2024. The three implementations differ in ways that matter to senders.
Google's Gemini Summary Cards appear above the email after the recipient opens it; they rolled out to Gmail mobile in May 2025. In January 2026, Google brought Gemini 3 into Gmail as the "Gemini era" launch: AI Overviews for thread summaries went free for everyone, natural-language question-answering against the inbox launched as a paid feature (Google AI Pro and Ultra), and AI Inbox entered trusted-tester phase. AI Inbox identifies the recipient's "VIPs" using email frequency, contacts list membership, and relationships it can infer from message content. The third signal is Google publicly confirming that content-derived inferences drive inbox prioritisation. The card sits above your message; the message is still underneath. The summary is read first.
The newer Gmail mode is natural-language question-answering against the inbox. The recipient asks something like "who was the plumber that gave me a quote for the bathroom renovation last year?" and Gemini returns a synthesised answer, drawing on the underlying messages without the recipient opening any of them. That puts the model one step further between sender and recipient: not summarising your message above your message, but answering questions that may be informed by your message without ever surfacing it. Paid-only at launch (Google AI Pro and Ultra).
Apple's implementation is the most aggressive. For recipients who have Apple Intelligence enabled (opt-in, supported hardware only: iPhone 15 Pro and later, M-series iPads and Macs), the summary replaces the preview text in the inbox list view, before the recipient opens anything. The preheader is one of the few surfaces marketers actively design for. Apple writes over it with the model's read of the message. The opt-in caveat matters for current reach. It does not change the direction of travel: the eligible install base grows with every device cycle, and Apple is not the only provider going this way. Apple also shipped Priority Messages in the same release, a section at the top of the inbox showing emails the model predicts the recipient should act on. iOS 18.2 (December 2024) then added Mail Categorisation (Primary, Transactions, Updates, Promotions), Apple's Gmail Tabs landing twelve years late. The Inbox-by-Gmail thesis (provider does the categorisation, user doesn't) won at Apple by 2025.
Microsoft Copilot's summarisation was paid-only through 2024 but became available to non-licensed Outlook users in August-September 2025 provided Copilot Chat is pinned. Inbox prioritisation, draft assistance, and natural-language rule creation sit in the same surface.
The patent record matches the product timeline. Microsoft's US 12,413,54223, granted September 2025, claims a system that pre-processes incoming email to identify and exclude messages deemed unimportant from further processing, generates digest, importance, and content summaries for the rest, and conducts the user through a navigation experience that displays each summary before the underlying message. The patent's stated benefit is that the user "does not need to open unimportant messages." Yahoo's US 12,513,10024, granted December 2025, claims an LLM-generated inbox digest displayed in association with the inbox, with interactive functionality on the summary structure. Apple's December 2025 application Techniques for Managing Emails25, priority dated to the week of the WWDC Apple Intelligence announcement in June 2024, covers the same territory in application form. Three providers, the same shape of patent, filed or granted in the same eighteen-month window.
There's an institutional signal in the research trail behind all of this. The Gmail extraction team (Wendt, Tata, and collaborators) published a steady run of papers on rule-to-ML migration, layout-aware encoding, and template induction from 2018 through 2020. Around 2023 that thread tailed off. Since then the same researchers have shown up on LLM-summarisation papers, including "Enhancing Incremental Summarization with Structured Representations" at EMNLP 2024, which uses JSON-structured memory to feed Gemini for long-document summarisation26. The team that built the parser is now building the summariser. The product timeline tracks the research trail.
The recipient may never read your message. They may read the model's summary of it.
This matters because the summary doesn't draw evenly from your message. Google's layout-aware encoder weights bold headers, large fonts, and earlier blocks heavier in the document representation12. The practical consequence: the model's summary of your campaign is likely to draw disproportionately from your headline block, your CTA, and your sentences with explicit verbs. Body copy that wraps the offer in narrative gets averaged out. Brand boilerplate in the header block becomes the summary. The offer buried in body-weight paragraphs may not survive at all.
The unit of inbox AI analysis is shifting from the message to the sentence and the block. Mixed-intent campaigns (service email with a CTA tacked on; promo email with policy disclaimers in the middle) risk being characterised by the dominant block, not the marketer's intent. Single-intent messages with explicit verbs in their key blocks survive summarisation better than well-written prose.
There's a second AI layer worth knowing about. Yahoo's future-email prediction work showed providers can model which templates a recipient is expected to receive next based on causal chains already in their inbox. A purchase confirmation predicts a shipment notification predicts a delivery confirmation27. Break the chain and the provider can detect it. For brands sending transactional sequences, this means the provider has a model of what an expected next message looks like; if you skip a step or send late, that's a signal the sender has no visibility into.
Google extended the same trajectory at I/O 2026 on May 19. Gmail Live launched as a voice-activated inbox search: a user can ask "what's my flight's gate number?" or "what's going on at my kid's school this week?" and the model returns a synthesised answer drawn from messages it reads on the user's behalf, without surfacing the underlying emails. AI Inbox, previously Google AI Ultra only, expanded the same day to AI Plus and Pro subscribers in the US, with new capabilities including personalised draft replies (the model generates a context-aware reply the recipient can review and send) and surfaced links to relevant Docs/Sheets/Slides next to tasks. Google also previewed Gemini Spark, a 24/7 personal AI agent that takes actions on the user's behalf (including sending emails and updating the calendar) and integrates with Workspace. The signal asymmetry sharpens with each release: more of the recipient's interaction with your message happens between the recipient and the model. Less of it produces engagement signal that flows back to the sender; more of it produces behavioural signal that flows to the provider.
Privacy is real for content. Behaviour is the surveillance surface.
Every Google and Yahoo paper repeats the same architectural boilerplate about how content is handled. No engineer inspects a user's email. Data is encrypted at rest. Access happens via reviewed, audited binaries running on role accounts. The published mechanisms include:
- k-anonymity as the floor for any human auditing of templates8 and for any extraction3, 7.
- Synthetic email generation, masking variable parts of real templates so editors can review extractions without seeing personal data10, 8.
- Differential privacy applied to BERT, perturbing token embeddings at the client so the server never sees the raw text28.
- Knowledge distillation, training small client-side or delivery-time models from larger teacher ensembles11.
- Federated and on-device approaches as the next step29.
- Server-side classification on features other than PII, with disposition decisions (including quarantine) made on the server before any download to the recipient device30.
Take these claims at face value or don't. Either way, the content layer is not where the interesting surveillance question sits. The behavioural layer is.
The inbox is the new ad surface, and a profile source beyond it
Yahoo's action-prediction patent doesn't only claim using engagement signals to rank inbox messages. It also claims using the same per-message action predictions to target advertisements31. Features include sender-name tokens like no-reply and reminder, the recipient's historical reply ratio for the sender, forward rate, average reply time, and shared-last-name signals between sender and recipient31. Horizontal, vertical, and pair-wise classifiers aggregate the same signals across the population, per inbox, and per sender-recipient pair.
The model that decides whether to show your message also informs what ads sit next to it. Engagement metrics drive both.
A more recent Yahoo patent extends this from per-message prediction to per-user persona classification. US 12,556,50132 claims an inbox system that uses a language model to classify the user into one of an enumerated set of behavioural personas: inbox organizer, minimalist, priority focused, selective reader, delayed responder, batch processor, social engager, inbox ignorer, information hoarder, or unsubscriber. The persona is derived from "inbox characteristics" including marked emails, email flags, volume, settings, and rules. The provider isn't only modelling whether you'll act on a given message. It is modelling what kind of inbox user you are. Yahoo's broader LLM-email programme covers AI-driven prioritisation, LLM-assisted email automation, and instructions-based messaging inboxes in the same filing wave33, with a granted member covering LLM-based scheduling operations issued in February 2026.
It doesn't stop at adjacent ads. Even where providers explicitly disclaim using message content for ad targeting, the surrounding signals can feed user profiling that informs ad delivery elsewhere on the provider's network.
Google's official position on this has shifted slightly over time and is worth quoting directly. In 2017, when Google ended Gmail content scanning for consumer accounts, Diane Greene wrote that "Consumer Gmail content will not be used or scanned for any ads personalization after this change." The 2020 Smart Features blog post broadened that to "Google ads are not based on your personal data in Gmail, no matter which choice you make." The current Privacy Policy and Safety Center pages retreat to the narrower formulation: "We don't show you personalized ads based on your content from Drive, Gmail, or Photos."
The disclaimers sit alongside a Privacy Policy that explicitly classifies email metadata as "activity." Under "Your activity": "If you use our services to make and receive calls or send and receive messages, we may collect call and message log information like your phone number, calling-party number, receiving-party number, forwarding numbers, sender and recipient email address, time and date of calls and messages, duration of calls, routing information, and types and volumes of calls and messages." Activity, by Google's own framing, feeds personalised ads. Sender, recipient, frequency, and timing of Gmail messages are activity, not content.
That leaves a gap. The ML pipeline this whole post is about (classification, extraction, summarisation, intent inference) takes raw content and produces derived representations: this is a deal email, this is a flight confirmation, this user has a return window expiring next week, this user just bought sneakers. Whether those derived representations count as "content," "personal data in Gmail," or "activity" is not addressed in any Google document I can find. The 2020 blog post's broader claim ("personal data in Gmail") arguably covers derived inferences if read expansively, but the formal policy never adopted that wording, and the formal policy uses the narrower "content."
The Smart Features in Other Google Products toggle is where this gets concrete. By Google's own description, turning it on (the default outside the EEA, UK, Switzerland, and Japan) opts users into letting Google "use your Workspace content and activity to personalize your experience in other Google products" including Maps reservations, Wallet suggestions, Gemini personalisation, and Search personal intelligence. Those other products also show personalised ads. The 2020 blog asserts that ads still aren't based on Gmail data even when this is on, but doesn't explain the mechanism by which Workspace content and activity reach the personalisation systems for non-ads but not for ads.
In January 2026, the same pattern appeared explicitly inside Gmail itself. Google's Gemini era announcement describes AI Inbox using content-inferred relationships ("relationships it can infer from message content") alongside contacts and email frequency to identify VIPs. That is the first concrete Gmail-internal public statement that derived inferences from content drive in-product personalisation. It doesn't touch the ad-targeting question directly, but it closes one corner of the ambiguity: derived inferences from content are being used for product features, in stated and on-the-record terms.
The architectural mechanism is documented in Google's own patent record. US 12,417,35634, granted September 2025 to Bendersky and Zhang (Bendersky also lead-authored the WSDM survey already cited29), describes user-feature soft prompt embeddings that condition an LLM's output on user attributes (the patent names location, age, gender, and family status) and on "personal information specific to the user, including emails, text from open documents on the user device." The personal repository the model can be granted access to is explicitly described as containing email. The patent doesn't say Gmail or AI Inbox, but the architecture matches the product behaviour: an LLM whose output is conditioned on derived inferences from the user's content, then used to surface the things the user is supposedly most likely to care about.
The most defensible reading is that Google does not feed raw Gmail message text into the ads model. The least defensible reading is that no Gmail-derived signal of any kind reaches it. Public documentation supports the first claim consistently. Whether the second claim holds depends on how "content," "personal data," and "activity" are drawn around derived inferences, and Google has not drawn those lines publicly.
Yahoo's history is more contested. An early class action over scanning email content for advertising purposes was settled in 2016, with Yahoo agreeing to technical changes that delayed when email content was retrieved for ad analysis. More recent litigation, filed in 2025, alleges that Yahoo's ConnectID technology uses email addresses as a cross-internet identifier for tracking and targeting in a post-cookie world. That case is ongoing.
Microsoft's privacy documentation notes that Outlook.com signals can flow into the broader Microsoft Advertising profile depending on a user's diagnostic and advertising settings.
The point is structural rather than scandalous. As third-party cookies decline, walled-garden providers hold one of the few continuous behavioural records still tied to a stable identity (the email address). The inbox is a continuous source of intent and engagement signals about the user, even where the content of the messages is architecturally protected from human inspection inside the provider. Content privacy and behavioural surveillance are different problems with different answers. The papers and patents make the second one clearer than most public conversation does.
Search has flipped from time to relevance
Three papers from Yahoo document the shift. The default chronological view has been augmented with "hero" results, relevance-ranked items pinned above the time-sorted list35. Internal experiments showed relevance-based ranking outperforms time-based by 22% MRR on corporate mail and 14% on web mail17. Heroes-Dup launched to all Yahoo enterprise mail users and part of Yahoo Web mail35. The underlying user behaviour Yahoo's 2014 work already documented: beyond 20 folders, folder-based discovery becomes less effective than search2, which is part of why providers have invested so heavily in making search smarter rather than encouraging users to organise more.
Google ran an experiment in the other direction with Inbox by Gmail (2014-2019), and I'm guessing at the post-mortem from outside rather than citing internal reasoning. Two threads ran in parallel inside Inbox. Bundles was an experiment in finer-grained ML categorisation than Gmail Tabs (which had launched in 2013) supported, with more verticals: Travel, Purchases, Finance, and so on. The standalone product was cut, but the categorisation thread didn't die. Gmail's current classification is much stronger than 2014-era Tabs, the Sept 2025 Purchases view brings back a Bundles-shaped vertical, and Yahoo's SPICE 119-class taxonomy is the same logic applied harder.
Inbox's other half tried to reframe email as a task/todo surface: Reminders as inline todos, Done to mark completion, Pin to surface, Snooze to defer. Of those, Snooze migrated to Gmail. Reminders moved into Google Tasks. Done and Pin didn't really survive. My read, again from outside, is that users wanted triage utilities (defer this) more than task semantics (turn this into a todo). The behaviour Yahoo's research already documents, 85% of messages never read, 89.5% of deletes without read, 36% lifetime under five minutes, 35% caught up, doesn't look like people converting emails into first-class todos. It looks like people who glance, decide, defer, or delete. Snooze fits. Reminders and Pin asked for more engagement than the average user wanted to put in.
Gmail did the same thing earlier. "Top results" in Gmail web and the matched-card layout in Inbox by Gmail surface relevant messages above the chronological list35. The current Gemini-powered search in Gmail goes further, returning summarised answers drawn from across the inbox rather than a list of messages.
Old messages get re-surfaced when they're relevant. A receipt or coupon you sent six months ago can appear above today's inbound when the user searches "amazon" or "flight." Findability is now a function of structured-field extraction (did your message become a card?), engagement history (does the user open similar messages from you?), and increasingly summarisation (does the LLM cite your message when answering the user's natural-language query?). Not keyword matching against subject and body.
This compounds with the queryable-customer-record observation. The well-structured email you send today is the source material the recipient's LLM assistant will draw on a year from now when they ask "when did I last buy from X" or "what's my warranty status on Y." Search is no longer the desperate move users make when the inbox has failed them. It's a primary surface, increasingly answered by the model rather than by a list of links, and the source material is structured email that survived being parsed.
The Promotions tab made the same flip in September 2025
On 11 September 2025, Google announced that Gmail's Promotions tab would default to "Most Relevant" sorting rather than "Most Recent." Users can switch back manually, but most don't: Movable Ink puts the share keeping the relevance default at roughly 75-85%. The ranking signals are familiar: per-recipient engagement history with the sender, opens, clicks, replies, frequency of interaction, plus broader behavioural cues from how cohort-similar users engage with comparable senders, plus time-sensitive "nudges" for offers with expiry dates.
This is the inbox-view version of the chronological-to-relevance flip that already happened in search. Same underlying logic, applied one layer up. The Promotions tab is no longer a chronological feed of the day's offers. It's an engagement-weighted ranking of the brands the recipient has previously interacted with, with low-engagement senders pushed below the fold and high-engagement senders pinned at the top.
The practical implication for senders is that "lands in Promotions" now decomposes into two outcomes. Lands in Promotions and ranks high for engaged subscribers is fine, arguably better than primary placement for promotional content because the user is actively scanning for offers. Lands in Promotions and ranks low across the cohort is functionally invisible, because the user only ever scrolls the top of the tab. Per-sender engagement history now determines not just whether you get retrieved but where you sit inside the surface you do get retrieved into.
Alongside the Promotions tab change, Gmail shipped the Purchases view, which consolidates receipts, order confirmations, and delivery updates into a single stream. Packages arriving within 24 hours surface at the top of Primary. This is the queryable-customer-record observation made concrete: structured transactional email is no longer just searchable, it's pre-aggregated into a dedicated UI surface the recipient navigates to directly. Receipts and shipping confirmations from a brand are now a persistent panel inside the inbox, not messages the user has to remember to search for.
Engagement is the new deliverability
Engagement has been a deliverability input for a long time. Inbox providers have used ML for junk classification, sender reputation modelling, and per-user engagement scoring for well over a decade. What changed on February 1, 2024 was that the major providers codified the engagement-as-deliverability picture into explicit, enforceable bulk-sender rules.
Gmail and Yahoo simultaneously rolled out new requirements for bulk senders (defined by Google as senders of 5,000+ messages per day to Gmail addresses): SPF and DKIM authentication required for all bulk mail, DMARC alignment required, the RFC 8058 one-click unsubscribe header (List-Unsubscribe and List-Unsubscribe-Post: List-Unsubscribe=One-Click) required, unsubscribes honoured within 48 hours, and a spam complaint rate ceiling of 0.3% with a strong recommendation to stay below 0.1%. Microsoft followed in May 2025, enforcing the same authentication requirements for senders of 5,000+ messages per day to Outlook.com, Hotmail, and Live with 550 5.7.515 rejections for non-compliance.
These rules don't introduce engagement-based filtering; they make the existing behaviour explicit and consequential. The spam complaint thresholds are hard limits: cross them and your domain reputation degrades algorithmically. The one-click unsubscribe requirement turns the historical "scroll, hunt, click, confirm" unsubscribe ordeal into a single tap, which means the cost of an unwanted send is much lower for the recipient and therefore much higher for the sender. List hygiene, frequency discipline, and earning genuine engagement have been deliverability inputs for years; the providers have just made the floor non-negotiable. The practitioner playbook for each of those hasn't changed much. What's changed is the cost of getting them wrong.
Underneath the explicit thresholds, Google's combined-quality-and-popularity patent describes a per-account score with a threshold-based gate that determines whether content from that account gets retrieved at all, with the threshold dynamically tuned by category and stakes36. The model is trained with a multi-objective loss combining human-rated quality and engagement-based popularity. Features include verification status, inbound link quality, sentiment of past content, and engagement-over-time. The patent gives explicit examples of how the threshold varies by category: "political" and "news" queries face higher quality bars than "sports" or "food" queries, with the bar adjusted upward by category sensitivity36. It also varies the threshold by geographic spread: a query trending in only a handful of cities is gated less strictly than one trending nationally or globally36. The patent's scope is broader than email (it covers content quality and popularity prediction generally), but the architecture maps to inbox placement logic: a category-aware retrieval gate driven by quality and engagement signals.
This is the architectural reason a sender can pass SPF/DKIM/DMARC and still never get retrieved into intelligent views, search results, or LLM assistant responses. Deliverability in the classical sense (does the message land in the inbox vs. spam) has long been only one layer of inbox routing. The category-aware retrieval gate sits above it and does more of the heavy lifting now than ever. Senders in high-stakes categories (news, finance, political) face stricter quality bars. Engagement alone may not compensate for low-quality content. High-quality content alone may not compensate for low engagement.
Senders have zero visibility into the classifier
There's a structural asymmetry worth naming. The recipient's inbox provider knows exactly how your message was classified, what category it landed in, which extractors fired, whether it cleared k-anonymity, what the action-prediction model expects to happen to it, and what summary the LLM produced. The sender knows none of this. Deliverability monitoring tools can show you whether messages landed in the inbox vs. spam at sampled seed addresses. Domain reputation tools can show you broad bucket health. None of them can show you whether a specific campaign was classified as a deal, a notification, or a newsletter; which schema annotations parsed cleanly; which extractors fired; or how Gemini summarised your message when the recipient asked "what did Brand X say today?" The black box is getting darker. As of mid-2026, no major commercial monitoring product offers visibility into classification, extraction, or summarisation at the per-campaign level. That gap is structurally hard to close, because the providers have gaming, privacy, and competitive reasons not to expose it.
What you actually own
The architectural picture across the sections above is one most marketers have a partial view of. The providers themselves articulate it openly on their sender-facing documentation. Yahoo's Sender Hub opens its Subscription Hub page with this: "Most of the emails our users receive in their inbox come from brands they love. We believe those business-to-consumer emails are a useful medium for users to get information, deals and entertainment." That's not a transport layer's self-description. That's a curator's self-description. The provider is positioning itself as an intermediary in the brand-consumer relationship that decides what counts as a B2C relationship worth supporting and what counts as friction the user should be helped to remove.
The provider, on the available evidence, acts as an active intermediary in the brand-consumer relationship, with infrastructure, algorithms, and UI surfaces that mediate that relationship: parser, ranker, summariser, ad targeter, unsubscribe broker, subscription manager. The transport function still exists, but it's one layer of a stack the provider operates and increasingly monetises end-to-end.
Which raises the question worth asking directly. If the inbox is a mediated relationship, what does the brand actually own?
The "owned channel" framing has been load-bearing in CRM strategy for two decades. PESO put email in the owned column alongside your website, your app, and your loyalty program. The case was simple: you have the address, you decide what to send, you decide when, it's free to send, the recipient consented. Email was owned because every other channel (social, search, paid) was demonstrably less owned.
Every one of those props is now mediated.
You have the address, but the inbox provider influences what the recipient sees of your message: which annotation surfaces, which deal card renders, which summary represents the campaign, which Brand Message Group it gets folded into, which tab it lands on. You decide what to send, but the provider can decide when it expires (via the Quintero-style time-relevance engine19) and when it disappears into "Older messages" once a fresher campaign arrives. You decide when, but the volume penalty surfaced via Manage Subscriptions, the unsubscribe banner, and the Brand Message Group collapse means the recipient's visibility of your sends decays as your frequency rises. It's still free to send in marginal-cost terms, but the engagement-cohort cost of poor sends is real and compounding. The consent is still there, but the inbox is now actively prompting the recipient to revoke it.
Email is sliding. Not falling off a cliff like Facebook organic reach did, but sliding. Same trajectory, slower, with more steps.
The actually-owned channels in 2026 are a shorter list than marketers admit
The honest list:
- Your website. Owned in the publishing sense, but discoverability via search and AI summaries is intermediated. SEO is functionally a rented capability now; the source code and the content remain yours.
- Your branded app. Owned in-session, including in-app messaging and push notifications. Mediated by App Store policies and notification-permission opt-in rates, which trend lower on iOS than push-based comms strategies assume.
- SMS. Carrier-mediated, but the carrier doesn't summarise the message and there's no algorithmic ranking layer between you and the recipient. The most truly-owned high-volume channel in 2026.
- Physical mail. Genuinely owned and undergoing a small DTC renaissance for exactly the reasons in this post. Expensive per touch, but the message lands intact and the engagement is measurable.
- Physical spaces. Retail, branded events, pop-ups, in-store experiences. Owned without question, expensive without question, with attribution challenges of their own.
- Loyalty programs and member portals. Owned because the brand is the platform. Logged-in messaging surfaces inside your own product are the highest-fidelity owned channel most brands have.
- Direct community spaces (Discord servers, paid Substack lists, owned forums). Owned content, rented infrastructure, real platform risk.
Email isn't on this list as "owned." It's on it as "less rented than social."
Editorial may survive mediation better than promotional
A working hypothesis worth taking seriously: the more your brand looks like a publisher, the less the mediation hurts. A longform editorial newsletter may survive AI summarisation reasonably well, because a summary of editorial content tends to represent the content. A promotional campaign tends to get reduced to the offer headline and the expiry date, and most of the work you put into the message becomes invisible to the recipient who only ever reads the summary. If that hypothesis holds, editorial newsletters are functionally less mediated than promotional ones, and the engagement profile compounds the reach advantage on top.
This doesn't mean every brand should become a publisher. It does suggest that the strategic value of editorial content within an email portfolio is higher than it was, because editorial is the format the new mediation layer appears to treat least harshly.
Audience-as-asset gets sharper
The classical metric of CRM, "list size," is increasingly disconnected from the size of the audience you can actually reach. A 100,000-subscriber list where 70% are zero-engaged isn't worth 100,000 reachable subscribers; it's worth the engaged subset the provider still routes your mail toward. The dormant 70% drag engagement-cohort placement on the active 30%, and provider-initiated unsubscribe is actively decommissioning the dormant segment for you whether you wanted that or not.
Engagement-weighted list size is the only metric that means anything. The standard "list growth" KPI on monthly reporting is mostly vanity. The harder question, "how many subscribers can I reliably reach with a relevant campaign," is the one that maps to reality.
Portfolio, not substitution
The strategic response isn't to abandon email; the addressability is too good and the cost-per-touch is too low. The shift is to treat email as one tool in an owned-channel portfolio rather than the foundation of CRM.
A practical decomposition:
- High-priority signals where the message can't afford to be summarised: SMS. Service alerts, fraud notifications, time-critical confirmations.
- App-engaged users: push notifications and in-app messaging. Owned surfaces with high fidelity for the segment that has opted in.
- Logged-in users on web or in apps: in-product messaging and on-site or in-app personalisation. Highest-fidelity owned surface most brands have, also the most underused.
- Browser-engaged anonymous users: web push, where it's been granted.
- High-value retention moments: physical mail and physical spaces. Expensive per touch, but defensible economics for top-tier customers and the strongest brand-experience surfaces a company has.
- Broad mid-funnel where summary distortion is acceptable: email. Still the workhorse, still the highest-volume channel, just not the foundation.
The mistake is treating any one channel as "the relationship." The relationship is the customer record and the addressability across channels. Email is one of several routes to it, and the route is getting noisier.
Where this is heading
Pulling the threads together:
- Less inbox, more intelligent views. Yahoo Mail 6 already does this20. Gmail's tabs were earlier moves in the same direction. Expect more provider-mediated UIs that aggregate by topic (Travel, Receipts, Deals) and de-emphasise the chronological inbox.
- More AI between you and the recipient. With LLM summarisation now sitting in every major mail client, expect significantly more of what you send to be parsed, summarised, or auto-handled before a human sees it. The summary is increasingly the message.
- Causal prediction of campaign sequences. Providers can model the chains of messages a recipient expects (purchase, shipping, delivery, post-purchase survey, return-window expiry)27. Breaks in the expected chain become signals. So does a complete chain.
- Microdata, schema.org, and structured markup matter more, not less. The classifiers use HTML structure as features9. Clean templates with consistent schema markup get extraction coverage even when the visual design changes. Image-only campaigns lose the structural context the model uses to interpret content. The brands that get this right operate on a much less crowded surface than the bulk of B2C senders.
- The k-anonymity floor will keep mattering for ML processing. Hyper-personalised, low-volume mail may still be surfaced by assistants and search; it just may not pass through the same ML extraction pipeline that powers Assistant cards, Deals views, and the like. Treat ML-extracted surface area as a deliberate design choice, not a default.
- The inbox becomes a primary ad surface as cookies die, and a profile source beyond it. The same engagement model that ranks messages informs ad selection inside the inbox and feeds the user profile that targets ads elsewhere on the provider's network.
- Engagement signals are the deliverability signal. Action history is the input to retrieval gates, ranking, summarisation prominence, and unsubscribe-banner triggering. Future visibility is a function of past cohort behaviour, not just infrastructure setup.
- The owned-channel portfolio replaces email-as-foundation. Treat email as one workhorse channel within a portfolio that includes SMS, push, in-product messaging, physical mail, physical spaces, and loyalty surfaces. The relationship is the customer record and the addressability across channels. Email is one route to it.
- The sender-side observability gap will widen before it closes. No commercial product currently exposes how your messages are being classified, extracted, summarised, or carded inside the major providers. Agentic systems like Gemini Spark, previewed at I/O 2026, will widen this further. That gap is structurally hard to close, because the providers have gaming, privacy, and competitive reasons not to expose it. Plan accordingly.
- The provider will model the user as a behavioural persona, not only as a stream of engagement events. Yahoo's recent persona patent32 is the most explicit example: a language model assigns the recipient to one of an enumerated set of archetypes (inbox organizer, minimalist, priority focused, and so on), driven by signals like marked emails, flags, volume, settings, and rules. Google's user-feature soft prompt embeddings34 point at a continuous version of the same idea. This sits above point 6. Engagement metrics rank individual messages; persona modelling shapes which product experiences the recipient gets at all. The brand cannot address it, cannot detect it, and has no way to validate which persona the model has assigned the recipient.
The blunt version: the inbox provider has stopped being a transport layer. They have become an active intermediary between the brand and the recipient, classifying, extracting, summarising, predicting, profiling, advertising around, and increasingly responding on the user's behalf. They say so on their own sender documentation. The marketers who survive that are the ones whose campaigns survive being parsed, whose lists survive being pruned for them, and whose channel portfolios don't depend on email being the foundation. Clear structured intent, stable schema, durable utility, content the recipient actually returns to, across the channels they can still actually reach.
The inbox is a parser. Build for the parser. And build the other channels too.
- 1a1b
Ailon, N., Karnin, Z. S., Liberty, E., & Maarek, Y. (2013). Threading Machine Generated Email. WSDM.
- 2a2b2c
Grbovic, M., Halawi, G., Karnin, Z., & Maarek, Y. (2014). How Many Folders Do You Really Need? Classifying Email into a Handful of Categories. CIKM.
- 3a3b3c3d3e
Whittaker, M., Edmonds, N., Tata, S., Wendt, J. B., & Najork, M. (2019). Online Template Induction for Machine-Generated Emails (Crusher). VLDB.
- 4a4b4c4d4e4f4g
Bentley, F., Daskalova, N., & Andalibi, N. (2017). "If a person is emailing you, it just doesn't make sense": Exploring Changing Consumer Behaviors in Email. CHI.
- 5
Sahami, M., Dumais, S., Heckerman, D., & Horvitz, E. (1998). A Bayesian Approach to Filtering Junk E-Mail. AAAI Workshop on Learning for Text Categorization, Technical Report WS-98-05.
- 6
Rao, J. M., & Reiley, D. H. (2012). The Economics of Spam. Journal of Economic Perspectives, 26(3), 87-110. Cited here for the 55%-to-85% top-three concentration figure (2006-2012, from comScore) and the structural framing of consolidation. The post's positioning of spam-filtering economies of scale as one factor among several, rather than the dominant factor the paper emphasises, is mine.
- 7a7b7c
Sheng, Y., Tata, S., Wendt, J. B., Xie, J., Zhao, Q., & Najork, M. (2018). Anatomy of a Privacy-Safe Large-Scale Information Extraction System over Email (Juicer). KDD.
- 8a8b8c8d
Di Castro, D., Lewin-Eytan, L., Maarek, Y., Wolff, R., & Zohar, E. (2016). Enforcing k-anonymity in Web Mail Auditing. WSDM.
- 9a9b9c
Kocayusufoglu, F., Sheng, Y., Vo, N., Wendt, J., Zhao, Q., Tata, S., & Najork, M. (2019). RiSER: Learning Better Representations for Richly Structured Emails. WWW.
- 10a10b
Sheng, Y., Vo, N., Wendt, J. B., Tata, S., & Najork, M. (2020). Migrating a Privacy-Safe Information Extraction System to a Software 2.0 Design. CIDR.
- 11a11b11c11d
Early, K., O'Hare, N., & LuVogt, C. (2023). Content-Based Email Classification at Scale (SPICE: Specialized Inbox Classification Engine). CIKM.
- 12a12b
US 12,393,768 B2. Layout-Aware Multimodal Pretraining for Document Understanding. Zhang, Li, Chen, Hombaiah, Bendersky, Najork, Wu (Google). PCT filed 2020, granted 2025.
- 13a13b13c
Potti, N., Wendt, J. B., Zhao, Q., Tata, S., & Najork, M. (2018). Hidden in Plain Sight: Classifying Emails Using Embedded Image Contents. WWW.
- 14
US 10,645,052 B2. Service Integration into Electronic Mail Inbox. Yu et al. (Microsoft). Filed 2016, granted 2020.
- 15a15b15c
Di Castro, D., Karnin, Z., Lewin-Eytan, L., & Maarek, Y. (2016). You've Got Mail, and Here Is What You Could Do With It! Analyzing and Predicting Actions on Email Messages. WSDM.
- 16a16b
Alrashed, T., Hassan Awadallah, A., & Dumais, S. (2018). The Lifetime of Email Messages: A Large-Scale Analysis of Email Revisitation. CHIIR.
- 17a17b17c17d
Carmel, D., Halawi, G., Lewin-Eytan, L., Maarek, Y., & Raviv, A. (2015). Rank by Time or by Relevance? Revisiting Email Search. CIKM.
- 18
US 11,405,345 B2. E-Mail with Smart Reply and Roaming Drafts. Bernstein, Dantas, Wood (Microsoft). Filed 2017, granted 2022.
- 19a19b19c
US 10,432,568 B2. Automated Classification and Time-Based Relevancy Prioritization of Electronic Mail Items. Quintero (Microsoft). Filed 2016, granted 2019.
- 20a20b20c
Bentley, F. R., Jacobson, M., Sperling, C., Shankar, A., Royer, A., & McCarthy, J. (2020). Rethinking Consumer Email: The Research Process for Yahoo Mail 6. CHI Case Study.
- 21
US 10,673,796 B2. Automated Email Categorization and Rule Creation for Email Management. Kumbakonam Mohan (Microsoft). Filed 2017, granted 2020.
- 22
Singh, M., Cambronero, J., Gulwani, S., Le, V., & Verbruggen, G. (2023). EmFore: Online Learning of Email Folder Classification Rules. CIKM.
- 23
US 12,413,542 B2. Electronic Message System with Artificial Intelligence (AI)-Generated Personalized Summarization. Mehta, Andrews, Hattangady, Palermiti, Whitmore, Martino Pena, Thomas, Wood (Microsoft). Priority March 2023, granted September 2025. Pre-processes new email to identify and exclude messages deemed unimportant; generative AI produces digest, importance, and content summaries; the user is conducted through a navigation experience showing the summary before the underlying message and "does not need to open unimportant messages."
- 24
US 12,513,100 B2. Computerized Systems and Methods for an Electronic Inbox Digest. Bouguerra, Patel, Khanna, Sahadevan (Yahoo Assets). Granted December 2025. LLM-generated digest displayed in association with the inbox, with interactive functionality on the summary data structure.
- 25
US 2025/0379841 A1 (and corresponding PCT WO 2025/255530 A1). Techniques for Managing Emails. Tyler, Chaudhary, Cho, Bhat, Chatterjee, Chemmannoor (Apple). Priority date June 7, 2024 (the week of the Apple Intelligence announcement at WWDC 2024); published December 11, 2025. Application stage, not yet granted.
- 26
Hwang, E., Zhou, Y., Wendt, J. B., Gunel, B., Vo, N., Xie, J., & Tata, S. (2024). Enhancing Incremental Summarization with Structured Representations. Findings of EMNLP 2024.
- 27a27b
Gamzu, I., Karnin, Z., Maarek, Y., & Wajc, D. (2015). You Will Get Mail! Predicting the Arrival of Future Email. WWW Companion.
- 28
Qu, C., Kong, W., Yang, L., Zhang, M., Bendersky, M., & Najork, M. (2021). Natural Language Understanding with Privacy-Preserving BERT. CIKM.
- 29a29b
Bendersky, M., Wang, X., Najork, M., & Metzler, D. (2022). Search and Discovery in Personal Email Collections. WSDM tutorial.
- 30
US 12,333,394 B2. Privacy-Preserving Labeling and Classification of Email (Microsoft). Granted June 2025. Claims a graph-based labeling scheme using features "other than personally identifiable information," training a classifier that classifies received email and then "quarantining the received email on a server without downloading to a local computer."
- 31a31b
US 10,977,261 B2. Mining Email Inboxes for Suggesting Actions. Weber, Maarek, Koren (Verizon Media / Yahoo lineage; continuation of a 2011 filing). Granted 2021.
- 32a32b
US 12,556,501 B2. Systems and Methods for Instructions Based Messaging Inbox Using a Language Model. Bouguerra et al. (Yahoo Assets). The patent's enumerated persona set includes "an inbox organizer persona, a minimalist persona, a priority focused persona, a selective reader persona, a delayed responder persona, a batch processor persona, a social engager persona, an inbox ignorer persona, an information hoarder persona, or an unsubscriber persona," derived from "inbox characteristics" including marked emails, flags, volume, settings, and rules.
- 33
Yahoo Assets has filed a sequence of related LLM-email applications attributed primarily to Bouguerra, covering AI-driven prioritisation of electronic communications (US 2025/0133047 A1), LLM-assisted email automation (US 2025/0071074 A1), and instructions-based messaging inboxes (US 2025/0106177 A1). A granted member of the family, US 12,549,504 B2 (February 2026), covers LLM-based scheduling operations.
- 34a34b
US 12,417,356 B2. Large-Scale, Privacy Preserving Personalized Large Language Models (LLMs). Bendersky, Zhang (Google). Priority May 2023, granted September 2025. User-feature soft prompt embeddings condition LLM responses on user attributes (location, age, gender, family status) and "personal information specific to the user, including emails, text from open documents on the user device."
- 35a35b35c
Carmel, D., Lewin-Eytan, L., Libov, A., Maarek, Y., & Raviv, A. (2017). Promoting Relevant Results in Time-Ranked Mail Search. WWW.
- 36a36b36c
US 12,236,322 B2. Training/Utilizing a Model Predicting Both Quality and Popularity of Content. Hombaiah, Ofitserov, Bendersky, Najork (Google). Filed 2022, granted 2025. Note: the patent's scope is broader than email, covering content quality and popularity prediction generally; the architecture maps to inbox placement logic.